
Welcome to Part 2 in the “Building High-Performance Applications” series. For those who are on the path to building a high-performance and massively scalable application, this post will give a recap of the evolution of software architectures. We will also be decomposing an application architecture for creating highly concurrent, high throughput services that will fit right into your SOA or Microservices architecture.
In Part 1 of this series, we started with identifying some of the most important performance bottlenecks that you face while building an application server. But don’t worry if you have missed that. You can read Part 1 here: Building High-Performance Applications – Part 1.
Before getting to the agenda of Part 2, we would like to share some interesting data with you so that it will help you understand what we are calling “High Performance” and how many concurrent network requests “Massively Scalable” means.
Netflix – Scale of API Calls
The data we found out was dated, January 2012 and when Netflix was handling 42 Billion API calls every month. Interestingly,
42 Billion API Calls / Month ~= 1.4 Billion API Calls / Day ~= 58 Million API Calls / Hour ~ = < 1 Million API Calls / Minute ~= 16 K API Calls / Second
So it would be safe to assume that, Netflix was handling ~ 16 K Concurrent API calls back in 2012. We can only imagine what would be the scale now 6 years later for a company with a 70x growth curve.
Amazon – Scale of Search API
According to another data we found, dated 2016 when in an interview Amazon CEO Jeff Bezos said that the E-Commerce giant was handling ~ 1.1 Million API Calls / Second.
Sounds interesting? Here are some more:
- Instagram reportedly had 500 million daily active users in 2017.
- Paytm has a monthly avg traffic of ~100 million on desktop and mobile.
There’s a lot more data available on the internet and we can continue giving examples of how important the scale of applications is today. But we are sure you have a pretty good idea of how the scale of applications has become so important in the last few years, especially with the emergence of cloud and SaaS as a preferred delivery model. Sadly, the traditional approach towards building web applications no longer works or has a very limited area where it can be utilized.
Let’s Understand The Architecture Layers
A Web application usually comprises 3 layers:
- Presentation Layer
- Business Logic Layer
- Persistence / Database Layer
Until a decade back, 2-tier architectures of client-server applications were more prevalent. In 2-tier architecture, the Business Logic Layer and Persistence Layer are tightly coupled and usually sit behind a web server. Web servers like Apache being process-based models would fork a different process for each client request, thus being extremely resource hungry. And also due to the tight coupling between business logic and database, changing something in the system proved a costly affair.
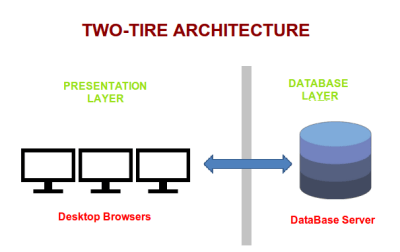
The 3-tier/N-tier architecture was adopted in which Presentation Layer, Business Logic Layer and Persistence Layer were decoupled and put on separate physical tiers. This allowed change in the application a lot easier to implement. Building applications become faster since separate teams could now be utilised for building each tier independently. The decoupling allowed each tier to be scaled separately, however, there still were a few shortcomings.
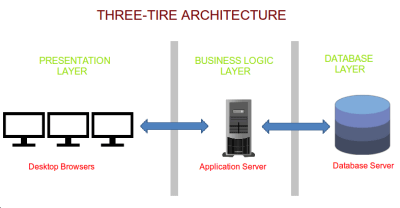
Shortcomings in 3-tier Architecture
- It did not consider the nature of the applications. Whether it was an E-Commerce application, a payment application or a video streaming application, the application logic was still coupled in a single layer.
- It was designed in the era when Cloud and elastic scalability were still in the making. It was not possible to scale specific parts of the application layer.
- It was designed in the era when mobile phones and handheld devices were not so common and web applications were still accessed on desktop browsers.
- The software was getting outdated with emerging advancements in multi-core CPUs available on demand. Process-based web servers were too old to cope with modern CPU architectures. Newer thread-based models were already being rolled out that offered much higher throughput. Performance demands were also increasing.
The Emergence of Service-Oriented Architectures
A service-oriented architecture is built on top of a 3-tier architecture and sees an application as a set of services and applications instead of decoupled tiers. It addresses the shortcomings of a 3-tier architecture.
A service implements some functionality which is used by applications and possibly other services. Visualize it this way: In SOA, an Application may be thought of as the presentation layer, while an SOA Service may be thought of as a business logic layer or a database layer.
Services communicate with each other using standard network protocols like HTTP / REST. The message formats are well-defined using metadata of sorts.
Now What Is a Microservices Architecture Then?
Some things are just a buzzword. Let us make it easier for you.
The only difference between SOA and Microservices is the size and scope of the services. A Microservices architecture is only a kind of SOA that defines services to be way too finely grained. It evolved only due to DevOps practices of Continuous Integration and Continuous Delivery. It requires services to be independent application components, whereas SOA services can belong to the same application component.
The real question however is :
- How to decompose an application into services?
- How to implement a service, for high performance and make your system massively scalable?
Build Application Architecture To Handle High Concurrency Demands
Now, we will move one step forward and talk about adopting a staged approach to event-driven concurrency. And introduce you to an architecture that will allow you to build high-performance services that support high concurrency demands.
If you are trying to build a service-oriented architecture or even microservices architecture to build a highly scalable application, this architecture will solve problems for you that come along with thread-based and event-based concurrency models. To name a few, high resource usage, high context switch overhead, and lock contention among others.
In this part, we strongly emphasise you to adopt a staged approach for building highly demanding internet applications. This approach was originally proposed by Matt Welsh, Principal Engineer at Google. The results we obtained were beyond imaginable and we like what this approach does by bringing the best of both worlds together i.e. threads and events. For the curious ones, we implemented this in C++.
The Problem With Threads and Events
Let us start by making a statement that “Threads are fundamentally the wrong interface”. We know some of you may object to this, but here’s our argument. Threads were never designed for high concurrency, rather they were designed for time sharing of resources. A common problem faced with multi-threaded architectures is the relatively high context switch overhead when compared with event-based architectures.
This overhead is primarily due to preemption, which requires saving registers and other states during context switches. So naturally, when you tend to increase the number of threads beyond a certain point, the context switch overhead becomes larger resulting in a throughput meltdown. The solution is to avoid the overuse of threads, but then this will result in limiting the number of clients you are serving. And this is not our design goal. Hence the statement!!
With an event-driven approach to achieving high concurrency, a service is constructed with a limited number of threads, typically equal to the number of CPUs, that processes events of different types from a queue. The task at hand is represented as a finite state machine and the transition from one state to another in the FSM is triggered by events.
There may exist variations of different event-driven patterns, but this is the overall idea. Event-driven systems tend to perform better concerning high load. As the number of tasks increases, the server throughput increases until the CPU usage goes full. Beyond this point, the server’s event queue retains the events hence the throughput remains constant for a large range of number of events.
Although the threads in an event-driven architecture emphasise the use of Nonblocking I/O, however, they can still block due to various reasons, interrupts, page faults, and shared locks. Thus raising various additional challenges for the application developers to handle, including the scheduling and ordering of events to process. Also, adding new functionality becomes difficult due to the tight coupling of event-handling threads.
The Staged Approach Towards Event-Driven Concurrency
The staged approach emphasises that the application may be viewed as a series of discrete stages where each stage has its event queue. Each stage only does a subset of processing before passing the request to the event queue of the next stage in the application.
Each stage comprises of following key elements –
- An Event Queue – Holds events to be processed
- A Thread Pool – A set of worker threads for the stage
- A Thread Pool Controller – For dynamic thread pool sizing for optimizing resources.
- Nonblocking I/O – SEDA emphasises the use of Nonblocking I/O
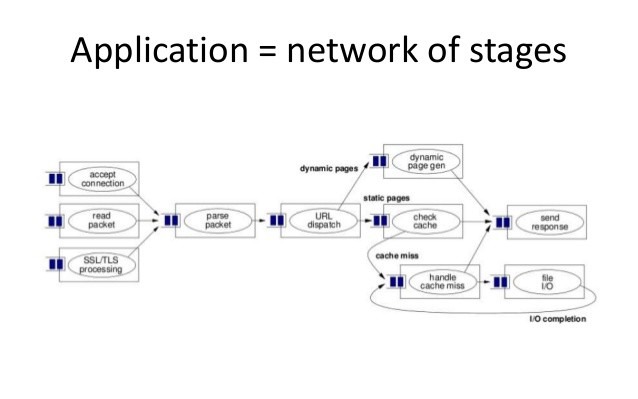
This approach allows you to write services and help you achieve the following design goals:
- Supports Massive Concurrency: Avoids, high context switch overhead with limited threads. Discrete stages ensure that there is no shared data between the stages and hence minimizing lock contention.
- Modularity of Application: Discrete stages ensure that the application is modular and that extending application logic is independent of other stages.
- Enable Load Conditioning: This allows you to dynamically examine the queue sizes in each stage and adjust the application logic accordingly. i.e. you may accept, reject or provide a degraded service under high-load conditions.
- Dynamic Thread Pool Sizing: A dynamic resource controller can be added to adjust the thread pool size of a stage to reduce or increase the number of threads as load decreases or increases.
Different event queue for each stage allows you to alter the application behaviour dynamically depending on the load. This is referred to as load conditioning. This is achieved by implementing dynamic thread pool sizing by adding a resource controller. It keeps checking on the incoming event queue size and may increase or decrease the thread pool size as and when appropriate.
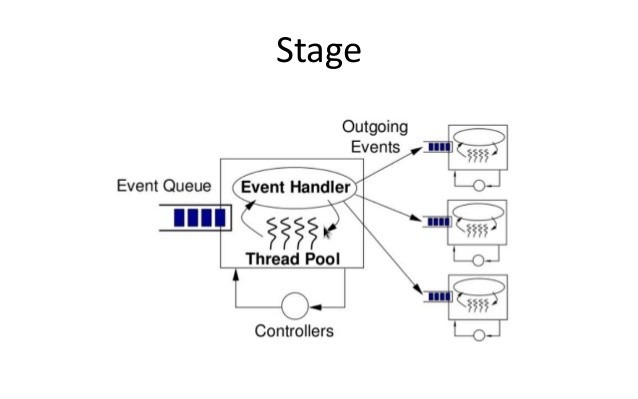
SEDA assumes that nonblocking I/O is applied and none of the threads blocks on a queue. For this, nonblocking I/O primitives are used. On Linux, you must have used select, poll or epoll for this. A non-blocking wait on the event queue is very critical to the effective SEDA design. Let’s take a look at pseudo-code for achieving the same:

Note: The above pseudo-code, gives a starting point to implement nonblocking wait on event queues. We have skipped the error handling code.
Additionally, a batching controller can be used to control the number of events consumed by each thread. But choosing a batching factor would be slightly tricky as a larger batching factor will result in high throughput and a small batching factor will result in lower response time of event processing. The ideal batching factor will be the smallest number with a constant throughput. We know this can be tricky, but once you implement and define your stages well this will start to seem obvious with some trial and error.
Final Words
We hope that this two-series blog will help you in building high-performance applications. Through our post, we are trying to help developers in quickly implement SOA and Microservices-based architectures for high throughput and scalability.
The professional team of The Nth Bit Labs has the right expertise in offering high-performance application services that are scalable, fault-tolerant and resilient. Talk to our expert team now for expert advice and scalable applications.



