
With the rapidly changing technology, it is very important to build a scalable application that handles the data complexity, concurrency and low-latency networks. Want to know how to build high-performance applications? Don’t worry, you are at the right place. Before starting this amazing blog, let’s tell you that this blog is a two-part series. So make sure that you read both the parts for complete knowledge.
Over the last couple of years, the team of The Nth Bit Labs has been building scalable, high-performance, fault-tolerant systems, systems that are highly concurrent in nature and are designed to handle a huge number of network requests per second. Based on our experience, we want to share our expertise with our fellow community members.
Some people reading this may definitely disagree with some of the suggestions we are going to make and some of the readers will suggest that they have a better way, which is absolutely fine with us. We are definitely not trying to be the voice of every Solution Architect or Developer.
The suggestions that we are going to make helped us not only in terms of performance but also ensuring that the system was easy to debug and most importantly extendable to business requirements.
Let us take you a couple of years back in time when the word “Server” used to be the alpha and the omega of your business application. You would install an HTTP server and code your business logic and be done with it. The scale was not an important question.
But today, applications are designed for a web scale, and the word “Server” sounds like a very weak term. We will not talk about mildly parallel applications such as your web browser which you are using to multitask along with reading this post. This kind of parallelism does not introduce many interesting challenges. We are calling it a challenge where the infrastructure itself is the limiting factor in handling several thousand requests per second. We are calling a challenge where how you design your application really matters, on the very edge of infrastructure capabilities.
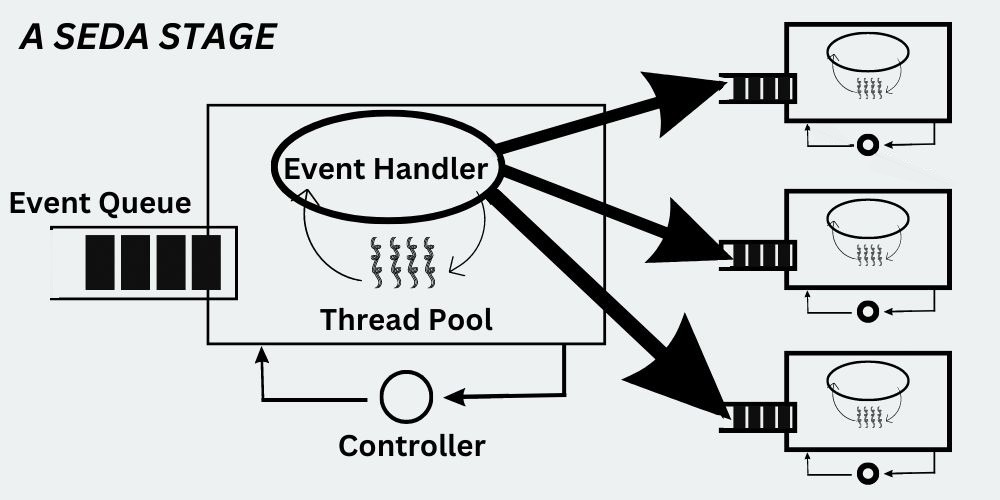
Of course, we can not cover everything in one article, so you are going to have to be patient, in case you decide to stay with us and read both parts. We are going to cover the basics in this Part and decompose some truly great architectures in the next parts including SEDA (Staged Event Driven Architecture) and Microservices, that are going to answer your questions if you have just started out or are about to begin your journey into developing a massively scalable application.
In order to understand how to obtain performance from your system, you must first need to understand what kills performance.
1. Do Not Keep Data Copies
We are assuming everyone has heard of the term “zero-copy”, either somewhere in the code comments or in the presentation slides of a marketing person.
Data copies are bad and you should avoid them. They will be there all over in your code, disguised & hidden. And guess what, by keeping data copies you are not only wasting your expensive memory but making room for more cache misses degrading your system performance by requiring data to be fetched from the main memory instead of cache.
The solution is to start identifying in code where you are keeping data copies. We would advise you to only focus on large objects such as your data blocks or container objects. And then, a good technique is to implement reference counting. It may seem difficult initially but will save you a lot of pain. This will ensure that instead of copying data, you are simply incrementing a reference count on the object’s buffer descriptor.
There are other techniques for keeping buffer pointers along with the length and offset however we wouldn’t advise them. It can quickly become buggy.
2. Minimise Context Switches
For those who do not understand what a context switch is, it is the very ability of the computer that enables multi-tasking. It allows for multiple threads to share a given number of CPUs.
When the number of threads increases, the CPU starts to spend more time going from one thread to another than it actually spends within any thread doing useful work. So the equation comes down to this – As the ratio of active threads to processors increases, the number of context switches also increases.
The only approach that will work here is to create a high throughput system to limit the number of threads to less than or equal to the number of processors. Now you must be thinking, “Why can’t we use just one thread? That will completely avoid context switching.” Because we don’t also want to stay underutilised. You must also make yourself familiar with I/O multiplexing techniques that will allow you to create one thread to handle multiple concurrent connections.
A good model that allows you to minimise context switches, emphasises the use of non-blocking queues. The model divides the entire system into a set of discrete stages. Each stage has its own thread and a queue in such a manner that one queue is independent of another queue. A very popular adaptation of such a model is called SEDA (Staged Event-Driven Architecture). We will cover this architecture in detail in the future parts of this series.
3. Avoid Calling System Memory Allocator Repeatedly
Making a call to the system memory allocator takes a full round trip into the OS. Allocating and freeing memory being the most frequently used operations makes it extremely inefficient since more time is spent in the OS. There are a couple of suggestions here that we would like to make.
4. Minimise Lock Contention
For those who do not understand thread contention, “It is simply when two threads try to access the same resource in such a way that at least one of the contending threads runs more slowly than it would if the other thread(s) were not running.”
The most obvious condition for thread contention is on a lock, which we have referred to as Lock Contention. This condition occurs because the contending threads are trying to access the same resource. If there is no lock and the threads modify the shared resource simultaneously, then it may result in a horrific race condition and eventually terminate the stack corruption process.
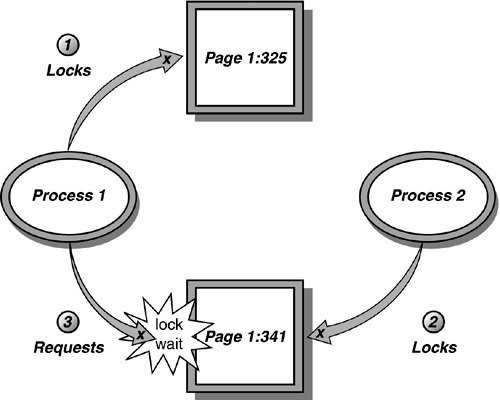
Here’s the ugly truth, there is no scheme which makes things simple. The only way to minimise or even reduce lock contention to zero is by ensuring that there is never a situation where there exists a shared resource for which one or more threads are racing.
The first thing to be done to achieve zero lock contention is to ensure that you are not using locks too liberally. Check if the data and corresponding operation is guaranteed to be atomic on your target platform. Second, adopt a model that we have mentioned earlier, and divide your problem into a set of discrete stages such that each stage has its own thread and a queue. This way each thread will be working on its own data set without there being a need to contend for locks on shared resources.
Conclusion
There may be other issues that any specific requirement of your server architecture may be facing, however, these are the most notorious performance bottlenecks that we have covered. We will continue further in Part 2 of this blog series, so make sure you read the next one also.



